2. Scrape data locally¶
This chapter will guide you through the process of adding a Python web scraper to your repository.
2.1. Download a scraper¶
The mechanics of devising a web scraper are beyond the scope of this class. Rather than craft our own, we will use the scraper created as part of the “Ẅeb Scraping with Python” class put on by Investigative Reporters and Editors. If you’d like to learn more about the scraping process, check out their tutorial.
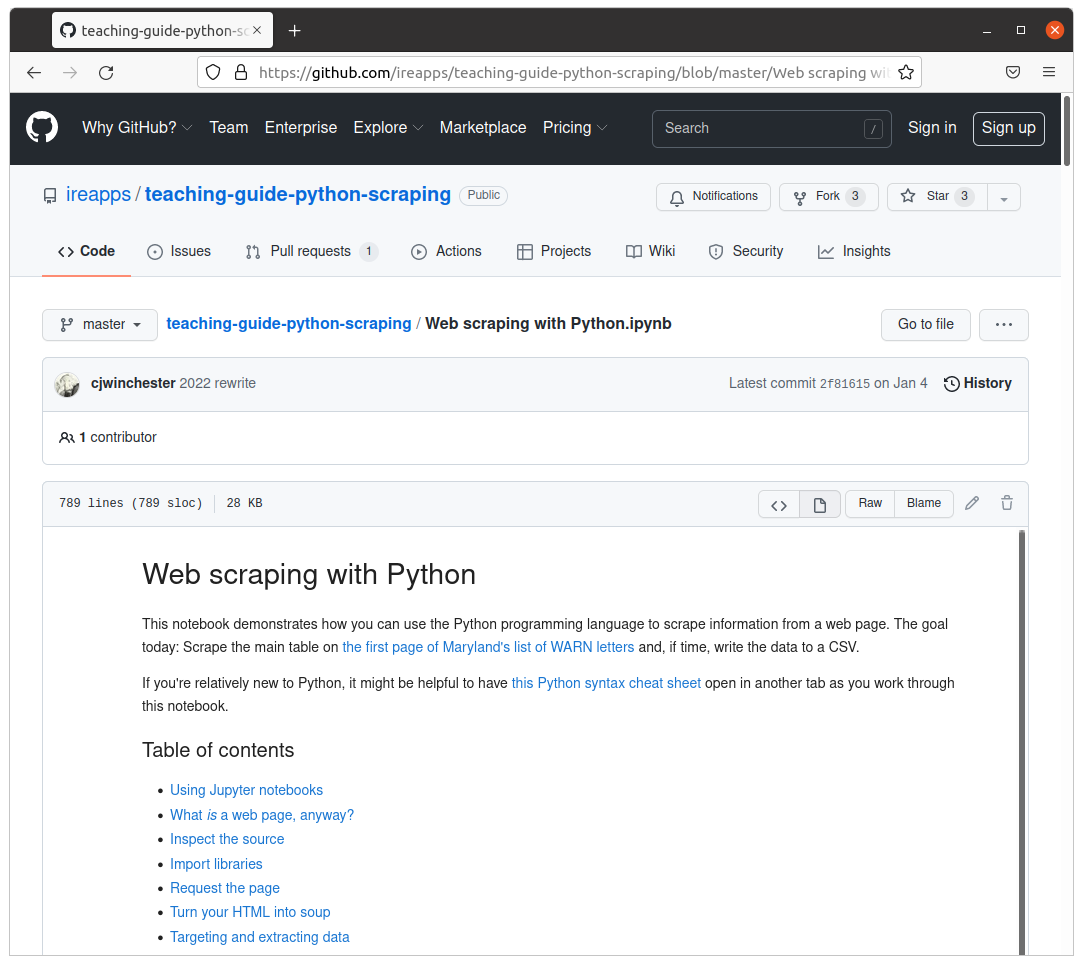
A completed, simplified version of IRE’s scraper is available at github.com/palewire/first-github-scraper. Open the scrape.ipynb file there and click the button labeled “Raw.” It will give you the scraper’s source code. Save that file into your repository’s root directory as scrape.ipynb.
The routine is trained to download WARN Act notices posted by the state of Maryland’s Department of Labor. The list is updated when companies based in the state disclose a mass layoff. Business reporters frequently use notices like these to report when plants close and workers lose jobs.
Note
If you’re interested in getting more involved with tracking WARN Act notices, investigate the scraping system maintained by Stanford’s Big Local News project. It scrapes filings from dozens of different state websites, consolidating them into a single file. That process is automated via, you guessed it, a GitHub Action.
There are different ways to run and test this scraper. This section will show you how to install Python tools on your computer to run this locally. If you want to learn how to run this notebook without installing them, skip to section 3.
2.2. Install uv¶
Our web scraper will depend on a set of Python tools that we’ll need to install before we can run the code.
They are the JupyterLab computational notebook, the requests library for downloading webpages and BeautifulSoup, a handy utility for parsing data from HTML.
JupyterLab is required to run the .ipynb notebook file. We can tell requests and bs4 will be necessary because they are imported at the top of the script, as seen on GitHub.
By default, Python’s third-party packages are installed in a shared folder somewhere in the depths of your computer. Unless told otherwise, every Python project will draw from this common pool of programs.
That approach is fine for your first experiments with Python, but it quickly falls apart when you start to get serious about coding.
For instance, say you develop a web application today with Flask version 1.1. What if, a year from now, you start a new project and use a newer version of Flask? Your old app is still running and may require occasional patches, but you may not have time to rewrite your old code to make it compatible with the latest version.
Open-source projects are changing every day and such conflicts are common, especially when you factor in the sub-dependencies of your project’s direct dependencies, as well as the sub-dependencies of those sub-dependencies.
Programmers solve this problem by creating a virtual environment for each project, which isolates the code into a discrete, independent container that does not rely on the global environment.
Strictly speaking, working within a virtual environment is not required. At first it might even feel like a hassle, but in the long run you will be glad you did it.
Note
You don’t have to take our word for it, you can read discussions on StackOverflow and Reddit.
There are several different ways to run a virtual environment. In this tutorial, we will take advantage of uv, a fast Python package and project manager.
Like the commands we’ve already learned, uv is executed with your computer’s command-line interface. You can verify it’s there by typing the following into your terminal:
uv --version
If you have it installed, you should see the terminal respond with the version on your machine. That will look something like this:
uv 0.11.29
If you get an error that says uv isn’t present, you will need to install it.
If you are on a Mac, you can install it via the Homebrew package manager, like so:
brew install uv
If you are on Windows and using the Windows Subsystem for Linux, you can use Homebrew’s cousin Linuxbrew to install Pipenv.
If neither option makes sense for you, the uv documentation recommends the standalone installer:
curl -LsSf https://astral.sh/uv/install.sh | sh
Whatever installation route you choose, you can confirm your success by asking for the uv version, as we did above.
uv --version
2.3. Install Python tools¶
Now let’s use uv to install our Python packages. We can add them to our project’s virtual environment by typing their names after the install command.
uv add jupyterlab requests bs4
Note
Save yourself some hassle by copying and pasting the command. There’s no shame. It’s the best way to avoid typos.
When you invoke the install command, uv checks for an existing virtual environment connected to your project’s directory. Finding none, it creates a new environment and installs your packages into it.
The packages we’ve requested are downloaded and installed from the Python Package Index, an open directory of free tools. Each of our programs has a page there. For instance, JupyterLab is indexed at pypi.org/project/jupyterlab.
When the installation finishes, two files will be added to your project directory: pyproject.toml and uv.lock. Open them in a text editor and you’ll see how they describe your project’s Python requirements.
In pyproject.toml, you’ll find the name and version of the packages we directed uv to install. We didn’t specify an exact version, so you’ll see something like:
[packages]
jupyterlab = "*"
requests = "*"
bs4 = "*"
uv.lock has a more complicated, nested structure that specifies the exact version of your project‘s direct dependencies, along with all their sub-dependencies. It’s a complete blueprint for how to install your project on any computer.
2.4. Run the scraper¶
With your Python tools installed, you’re ready to run the scraper. JupyterLab comes equipped with a special command — jupyter execute — that can run any .ipynb file from the command line.
Since JupyterLab was installed inside of a uv virtual environment, you’ll need to invoke it with the uv run command to access the special container where our programs were installed.
Here’s how to do it. Give it a try.
uv run jupyter execute scrape.ipynb
Once it finishes, list out the files in your directory with the ls command.
ls
You should see a new file named warn-data.csv created by the scraper. Open it in the spreadsheet program of your choice. You should see the data from Maryland’s site structured and ready to analyze.
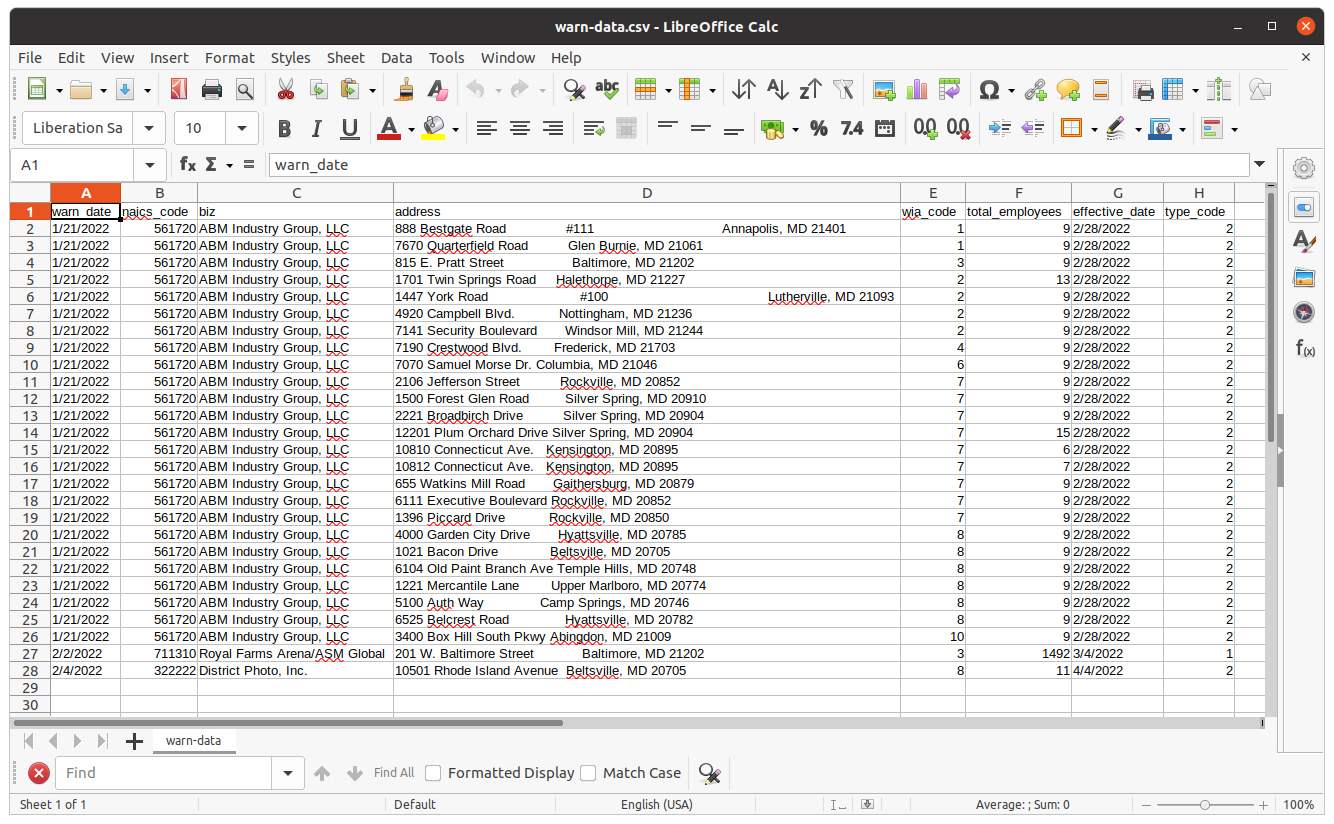
2.5. Save to GitHub¶
Now we’ll log our work with git, a command-line tool that allows us to carefully track changes to files in our repository. It is the open-source technology at the heart of GitHub’s social network and publishing system.
The first command to learn is status, which prints out a report card on the current state of your repository.
git status
Run it and your terminal should list out the four files we added to the repository. The next step is to instruct git to track the new files with the add command.
git add scrape.ipynb
git add warn-data.csv
git add pyproject.toml
git add uv.lock
Note
Rather than introduce files one by one, you can add more than one file by using a wildcard character in your command. One common shortcut is git add ., which will add all of the files in your repository at once.
Logging changes also requires using the commit command, which expects a summary of your work after the -m flag.
git commit -m "First commit"
Warning
If this is your first time using Git, you may be prompted to configure you name and email. If so, take the time now.
git config --global user.email "your@email.com"
git config --global user.name "your name"
Then run the commit command above again.
The final step is to synchronize the changes we’ve made on our computer with the copy of the repository hosted on Github. This is done via the push tool. This complicated git command requires two inputs.
First, the command asks for the name of the remote repository where you’d like to send your changes. In the parlance of git, the default name is origin.
Second, you need to provide the branch of the code you’d like to synchronize. Branching is a tool for maintaining parallel versions of your code within the same repository. We won’t get that sophisticated in this tutorial, so you can stick to the default code branch, which is called main.
Taking all that into account, the command to push local changes to GitHub is typically the following. Try it.
git push origin main
Your terminal should log the action, reporting back on its interaction with GitHub. Congratulations. You have made your first code commit. Reload your repository’s page on GitHub to see your handiwork.
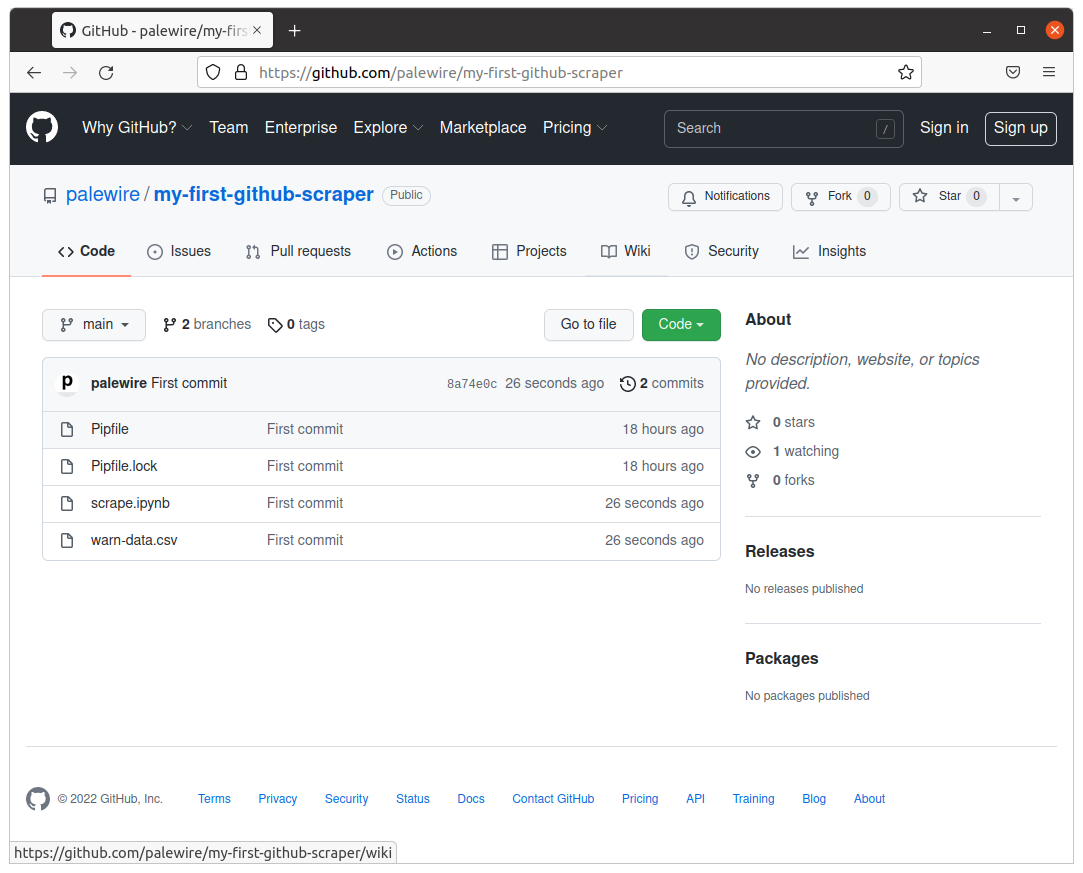
Next we’ll learn how to create a GitHub Action that can automatically run your scraper every day.