3. Scrape data using Google Collab¶
This chapter will guide you through the process of adding a Python web scraper to your repository.
3.1. Find the scraper¶
The mechanics of how to devise a web scraper are beyond the scope of this class. Rather than craft our own, we will use the scraper created as part of the “Ẅeb Scraping with Python” class put on by Investigative Reporters and Editors. If you’d like to learn more about the scraping process, follow their tutorial.
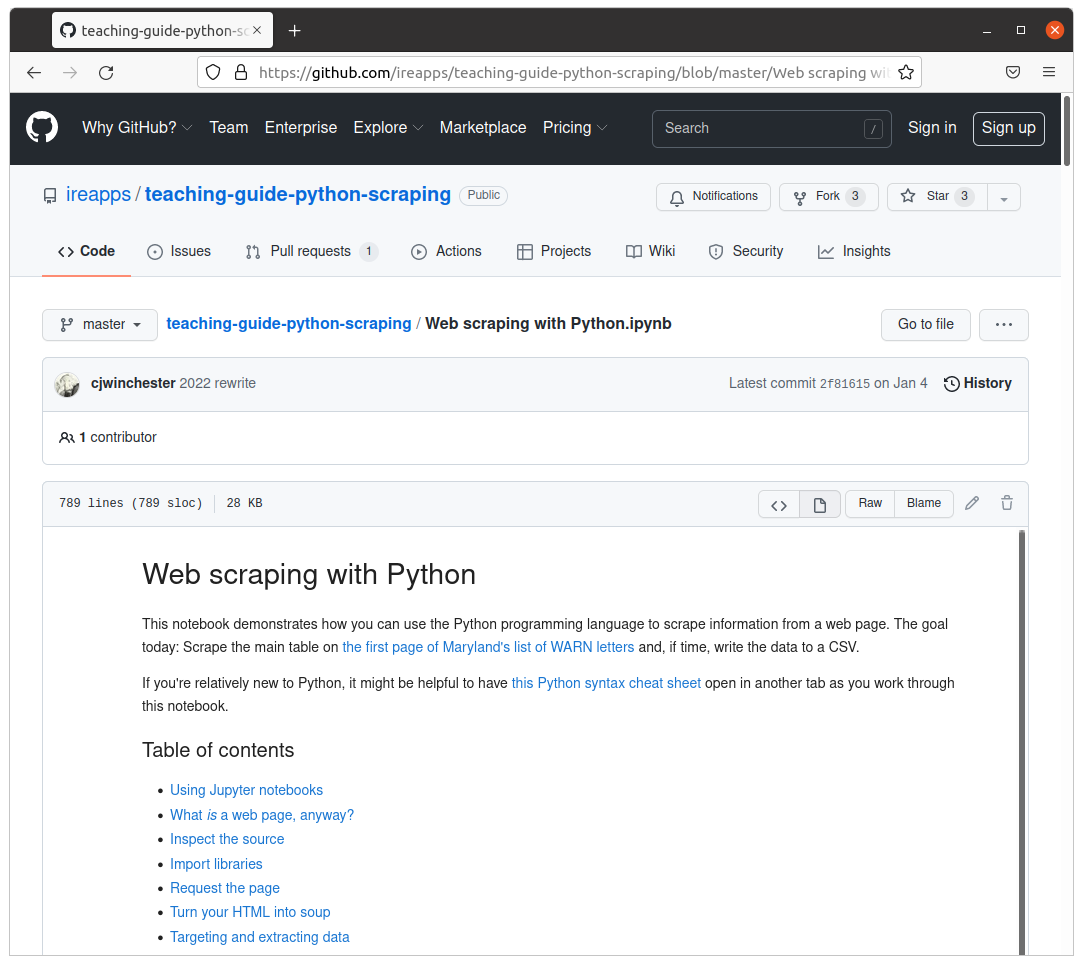
A completed, simplified version of IRE’s scraper is available at github.com/palewire/first-github-scraper.
The routine is trained to download WARN Act notices posted by the state of Maryland’s Department of Labor. The list is updated when companies based in the state disclose a mass layoff. Business reporters frequently use notices like these to report when plants close and workers lose jobs.
Note
If you’re interested in getting more involved with tracking WARN Act notices, investigate the scraping system maintained by Stanford’s Big Local News project. It scrapes filings from dozens of different state websites, consolidating them into a single file. That process is automated via, you guessed it, a GitHub Action.
3.2. Verify what tools are being used¶
If you want to run the web scraper locally, we will need to install a set of Python tools.
They are the JupyterLab computational notebook, the requests library for downloading webpages and BeautifulSoup, a handy utility for parsing data from HTML.
JupyterLab is required to run the .ipynb notebook file. We can tell requests and bs4 will be necessary because they are imported at the top of the script, as seen on GitHub.
By default, Python’s third-party packages are installed in a shared folder somewhere in the depths of your computer. Unless told otherwise, every Python project will draw from this common pool of programs.
To run this notebook locally on your computer check out section 2 of this documentation. Section 2 and 3 are interchangeable - whether you would want to run this locally or on a web browser (which is covered on this section) is up to you.
A simpler way to run a notebook without installing Python and its libraries is to use Google Collab. Google Collab is a product from Google research that allows you to run python code on your browser - and it’s free! It’s an easy way to start using Jupyter notebook without having to install all its requirements.
3.3. Import and the scraper on Google Collab¶
Make your way to Goolge Collab - you will need a to have a Google account and sign in to it. Choose the Github button and add the link to our scraper. Hit the search button.
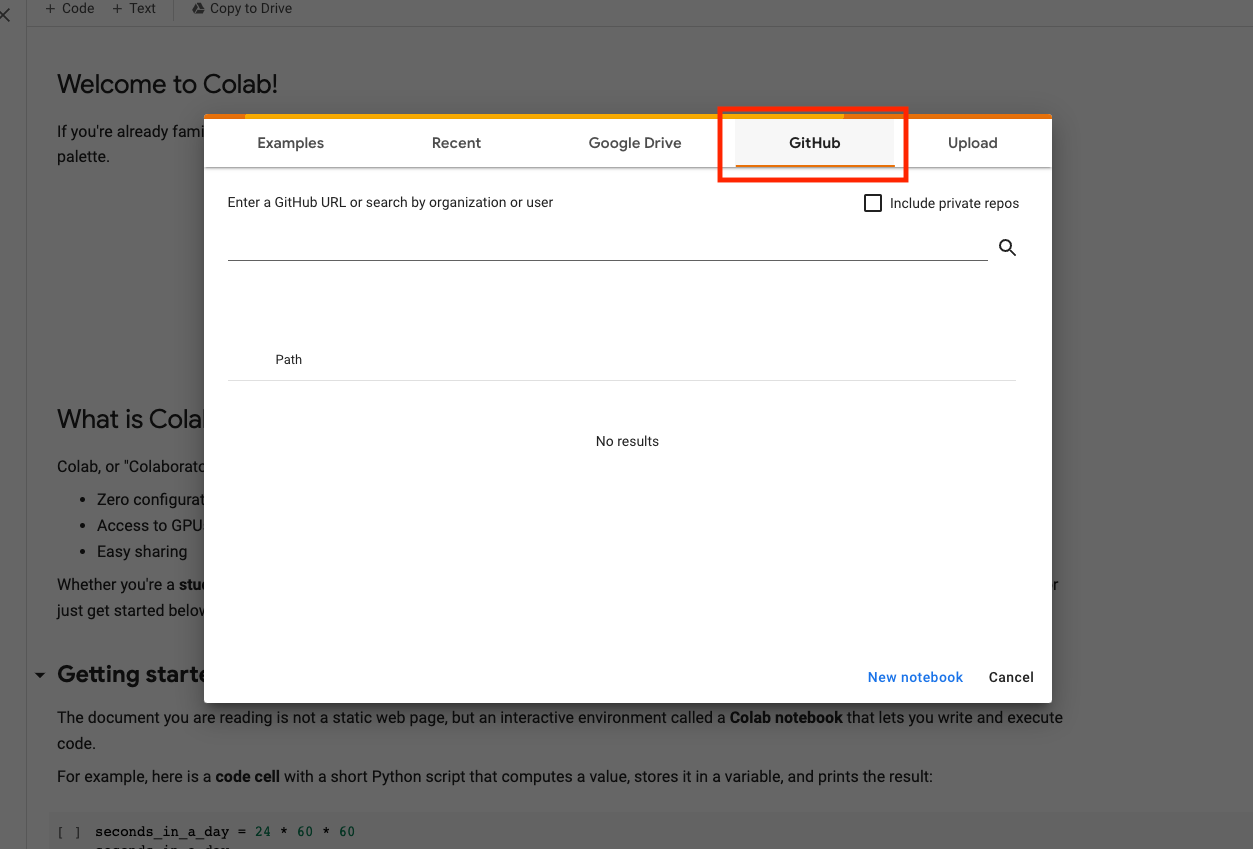
This will open up the notebook on your browser. First, let’s make sure to save a copy of this scraper in our Google Drive. Go to File -> Save a copy in Drive. This will allow you to run the scraper on your Collab account without having to search for the GitHub link.
3.4. Run the scraper¶
Notebooks are composed of “cells” in which you can add your code. You have to execute each line of code in your cell by “running” the cell. You can do this in many ways. Try clicking the play button on the left side of the cell. If you are familiar with Jupyter notebooks, you’ll find that keyboard shortcuts like SHIFT + ENTER will work on the cell as well. You can also run the notebook from top to bottom all at once by clicking on Runtime –> Run all. Notice our last cell, which creates a warn-data.csv. Click on the folder icon at the bottom of left panel to see your file.
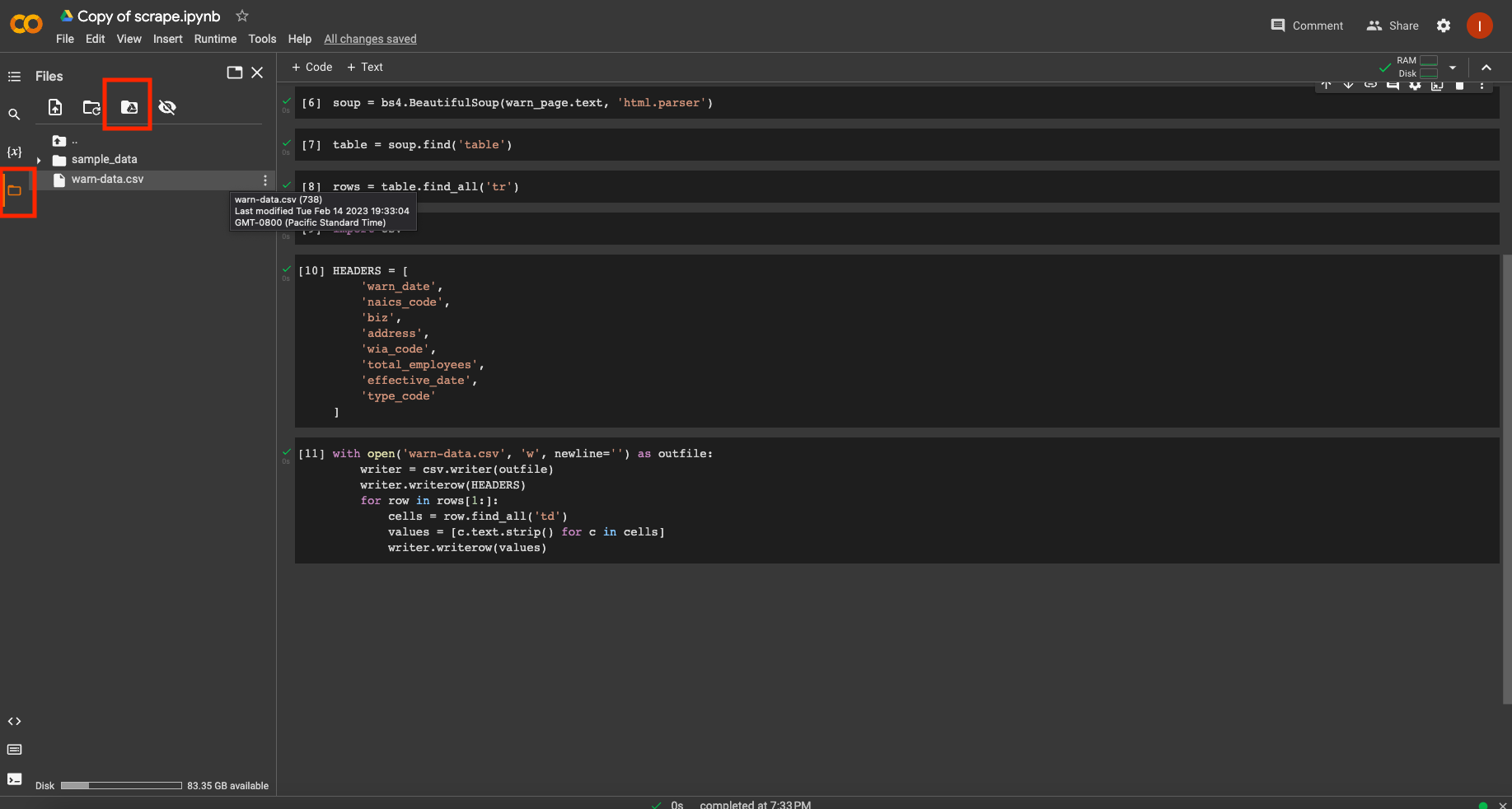
You should see a new file named warn-data.csv created by the scraper. Clicking on the Mount Drive icon on the top of the folder panel will create a new cell in your notebook. If you run the cell, it will create a link to your Google Drive and allow you to drag your output into Drive. You can also download the csv to your computer by right clicking on the csv file.
Open it in the spreadsheet program of your choice. You should see the data from Maryland’s site structured and ready to analyze.
3.5. Save to GitHub¶
Now we’ll log our work in our repository using GitHub Desktop. First let’s download the files we want to keep in our repository. Go to your Google Drive page, right click and download your scraper notebook. It should be an ipynb file.
Open your desktop and click on “View the files of your repository in Finder”. Drag the downloaded scrape.ipynb file to the folder. You will see the file in the right panel. You can leave a specific commit message (as a default it will say “Create scrape.ipynb”). Click on “Commit to main”. Then click “Push to origin”.
Now you will see your scraper in your Github repository.
Next we’ll learn how to create a GitHub Action that can automatically run your scraper every day.