First Automated Chart¶
Learn how you can use Python and the Datawrapper API to create a limitless number of charts.
What this class covers¶
Creating a key that allows you to edit charts using the Datawrapper API
Creating a chart with the Python
datawrapperlibraryWriting a template function that can create a chart for each item in a list
Regularly updating charts on a schedule
What you need¶
If you’ve brave enough to give the Python programming language a try, you are qualified to take this class. You’ll need some coding skills to create charts on your own, but the materials below can help anyone understand what’s possible.
Table of contents¶
What is an API?¶
Before we start, lets answer the obvious questions. What the heck is an API? And why do programmers talk about them so much?
Officially, API is an acronym that stands for application programming interface. But that’s pretty jargony too and probably doesn’t clear things up much.
The term was coined long before the web existed to describe computer programming systems designed to allow interaction with other pieces of software. Done properly, APIs open up services to outside coders who aren’t involved in developing the original software.
In the Internet age, APIs are commonly used to allow computer programmers to access services published on the web. For instance, the Twitter API allows the @earthquakebot account to post the latest quakes automatically. The Google Maps API allowed Adrian Holovaty to publish interactive maps of government data on chicagocrime.org.
In the same way, the Datawrapper API allows Reuters to automatically draft bar and line charts plotting equity indexes, commodity prices and macroeconomic indicators. This class will teach you the fundamentals of how you could use it to automate charts of your own.
Create a Datawrapper API key¶
The first step is to create an API key that grants your code permission to make charts using your Datawrapper account. This is a simple process that can be done in a few clicks. It all begins on the Datawrapper homepage at datawrapper.de.
Hit the “Login” button in the upper right corner of the screen.
If you already have an account, enter your email and password. If you don’t, click the “Create a new account” button at the bottom of the form. If you make a new account, be sure to confirm your email address when Datawrapper sends you a message.
Once you are logged in, you should see a page that looks like this:
Hover on the menu icon in the upper right corner of the screen and click “Settings.”
That will send you to the settings panel. Here you want to click on the “API Tokens” link in the left-hand navigation.
Note
If you made a new account and haven’t confirmed your email address, you will see an error message. Check your inbox for a message from Datawrapper and click the link to confirm your account.
On the next page, hit the “Create new Access Token” button.
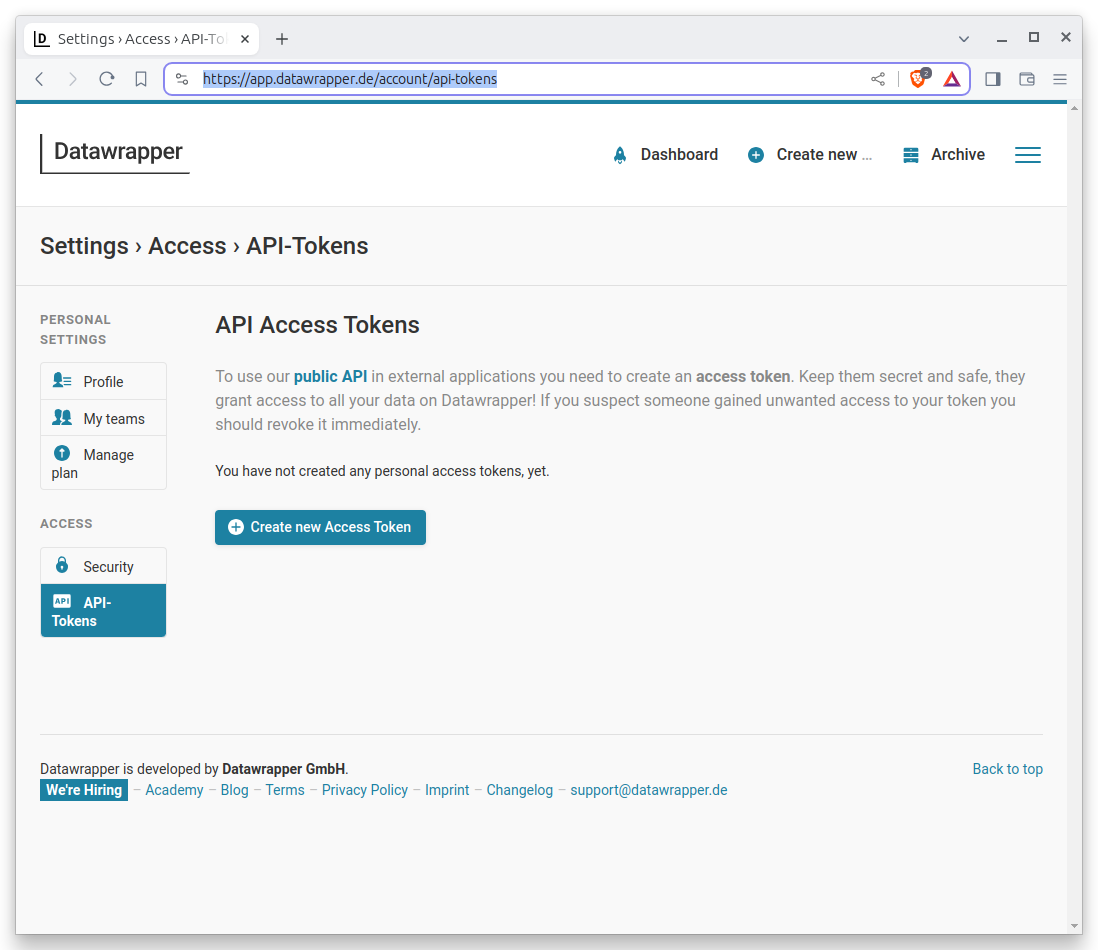
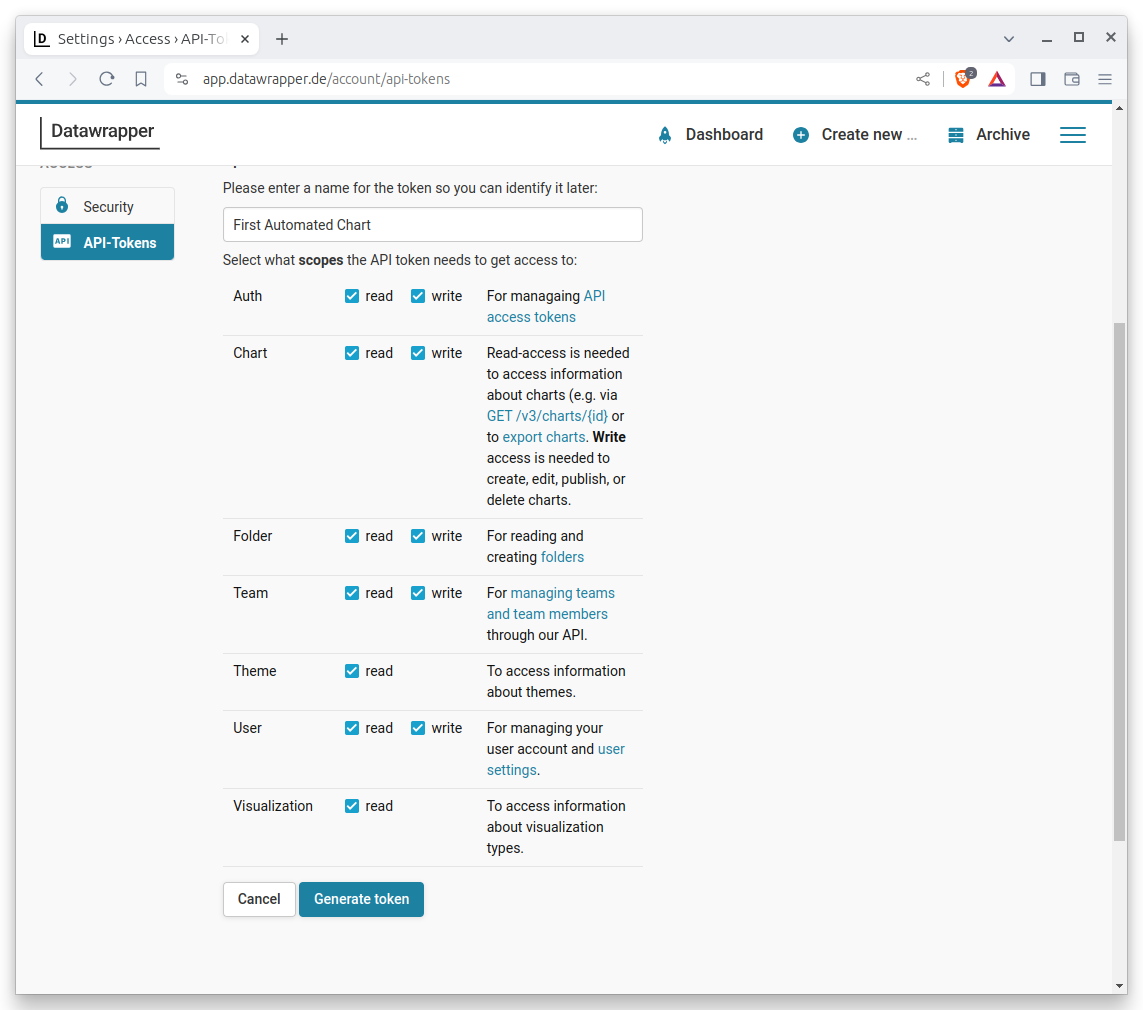
That will bring up a form. You should give your token a name that will help you remember what it’s for. For instance, you might call it “First Automated Chart.” Then click all of the permissions checkboxes. This will allow your token to do everything it needs to do. Then hit the “Generate token” button at the bottom.
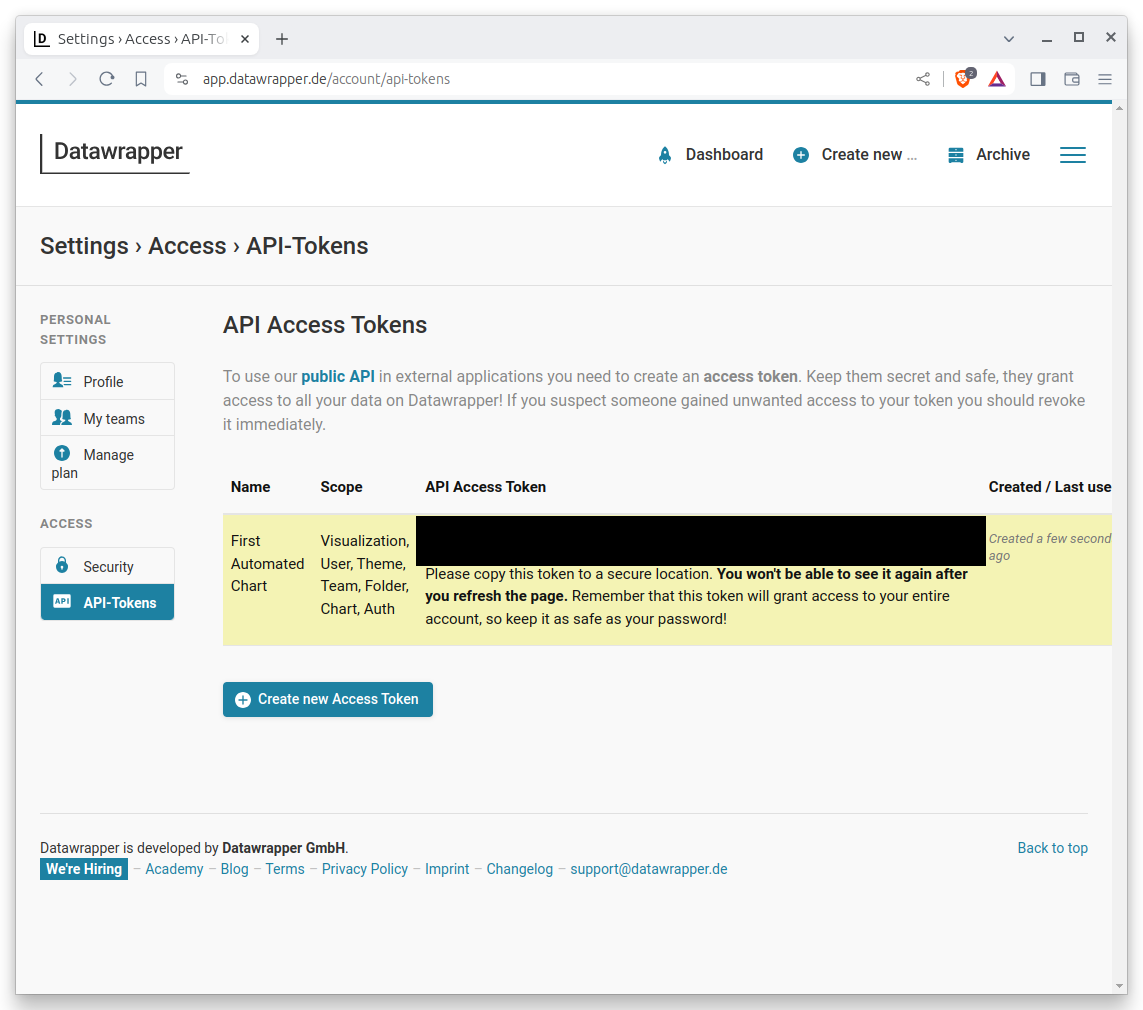
That will bring you to a new page with your token printed in the middle. The page will look something like the following, though I have redacted the actual token for security reasons. You should copy the long string of characters and save it in a safe place, like a password manager. It is the key you will need to access the Datawrapper API using your account.
Get started with a Jupyter notebook¶
A Jupyter notebook is a browser-based interface where you can write, run, remix and republish code.
It is free software you can install and run like any other open-source library. It is used by scientists, scholars, investors and corporations to create and share research. It is also used by journalists to develop stories and show their work.
There are numerous ways to install and configure Jupyter notebooks. Since this tutorial is designed for beginners, it will demonstrate how to use JupyterLab Desktop, a self-contained application that provides a ready-to-use Python environment with several popular libraries bundled in. It can be installed on any operating system with a simple point-and-click interface.
The first step is to visit JupyterLab Desktop’s homepage on GitHub in your web browser.
Scroll down to the documentation below the code until you reach the Installation section.
Then pick the link appropriate for your operating system. The installation file is large so the download might take a while.
Find the file in your downloads directory and double click it to begin the process. Follow the instructions presented by the pop-up windows, sticking to the default options.
Note
Your computer’s operating system might flag the JupyterLab Desktop installer as an unverified or insecure application. Don’t worry. The tool has been vetted by Project Jupyter’s core developers and it’s safe to use.
If your system is blocking you from installing the tool, you’ll likely need to work around its barriers. For instance, on MacOS, this might require visiting your system’s security settings to allow the installation.
Once the installer finishes, you can accept its offer to immediately open the program, or you can search for “Jupyter Lab” in your operating system’s application finder. That will open up a new window that looks something like this:
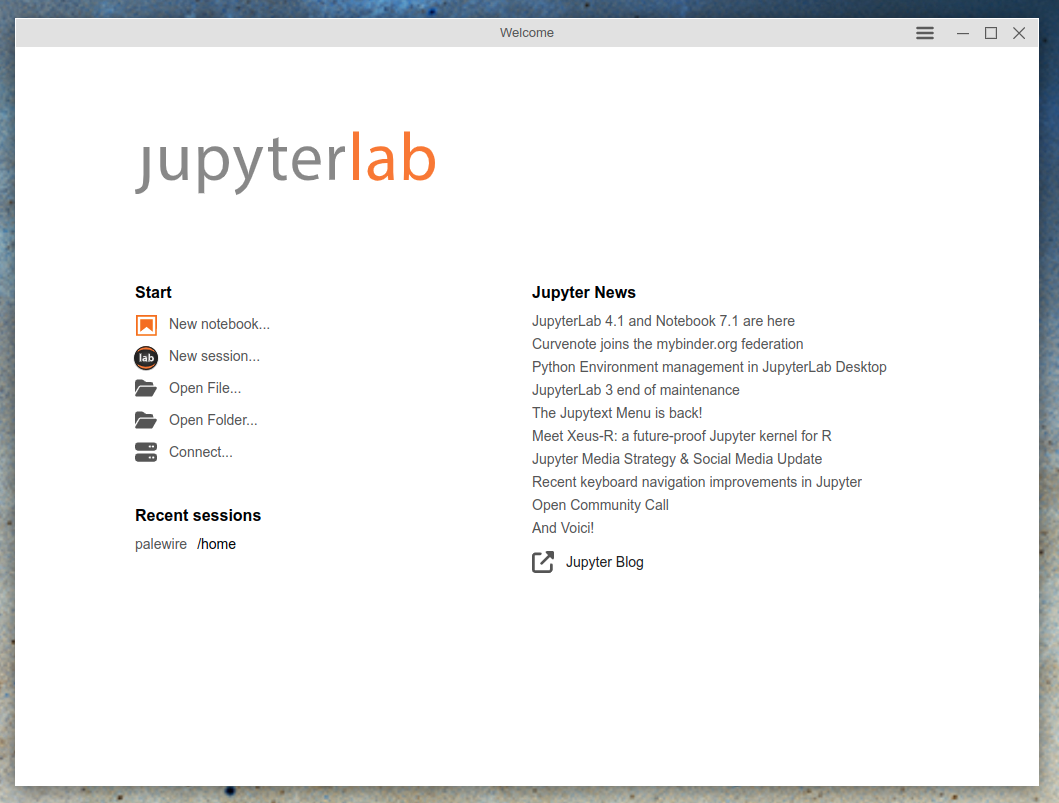
Now click the “New notebook…” button to start a Python interface. It will open up the notebook with an empty cell, which is where you can write and run your code.
![]()
The remainder of this class will assume you know how to enter code into cells and execute them in the notebook. If you don’t, don’t worry. It’s very easy. You can quickly learn how by working through the introductory chapter of “First Python Notebook,” another free course available on this site.
From here on out, you should follow along by running the examples in your notebook. I encourage you to copy and paste the code.
Connect to the Datawrapper API¶
The datawrapper library, created by one of the authors of this class, is a tool that allows you to interact with the Datawrapper API using Python. It is available for free on the Python Package Index, a repository of open-source software. You should install it with this command in the first cell.
!pip install datawrapper
Note
If you’re not in a Jupyter notebook, you can install datawrapper using pip, pipenv or another Python packaging tool.
The key first step is to authenticate with the Datawrapper API using the token you created earlier. You should add the token to your environment by adding DATAWRAPPER_ACCESS_TOKEN as an environment variable. In JupyterLab, you can do this by using the magic command %env like so:
%env DATAWRAPPER_ACCESS_TOKEN=your_token_here
Once the library is installed and the token is available, you should import the code into your notebook.
import datawrapper as dw
Verify that your connection is working by having the dw object ask the API for information about your account.
dw.Datawrapper().get_my_account()
It should return a dictionary with metadata about you, including your email address and role. It will look something like this:
{'id': 696724,
'email': 'b+nicar24@palewi.re',
'name': None,
'role': 'editor',
'language': 'en-US',
'presenceColor': None,
'avatar': None,
'teams': [],
'chartCount': 0,
'url': '/v3/users/696724',
'entitlements': {}}
If an error appears, verify that you entered your token correctly. If you are sure you have, check that your token has the correct permissions in the Datawrapper settings panel.
Import data¶
Now that you’re connected to Datawrapper, it’s time to introduce the data you’ll use to create your charts. You’ll use a dataset of arrests made by the Baltimore Police Department that is published on the city’s data portal. To speed up the class, we’ve created a simplified version that doesn’t require any data cleaning.
We’ll read in the data using the pandas library, a popular tool for working with data in Python covered in depth by “First Python Notebook.” Before you can use it, you’ll need to import it in your Jupyter Desktop environment using the same technique you used to install the datawrapper library.
import pandas as pd
Note
If your notebook throws an error and says pandas can’t be found, you can install it using the technique we employed for the datawrapper library.
pip install pandas
After that completes, try importing pandas again.
Read in the data using the read_csv function and save it as a variable named df. First we’ll use the URL of the dataset, which is hosted on GitHub, and then we’ll pass in a list of the columns that contain dates so that pandas can parse them correctly.
df = pd.read_csv(
"https://raw.githubusercontent.com/palewire/first-automated-chart/main/_notebooks/arrests.csv",
parse_dates=["ArrestDateTime"]
)
The table, known in pandas as a DataFrame, can be inspected by running the head method on the df object. That will show the first five rows.
df.head()
You can see that the dataset features one row for each arrest, with columns for the date and time of the arrest, the district where it occurred and the charge that was filed.
Create one chart¶
With these materials, any number of charts could be created. As a simple start, lets consider a chart that shows the number of arrests in Baltimore by year. Lets look into the idea by creating a new column in the df object that contains the year of each arrest.
df['year'] = df.ArrestDateTime.dt.year
Then tally the arrests logged in each year.
df.year.value_counts()
That will return some eye-opening numbers. The number of arrests in Baltimore has been falling dramatically in recent years, exactly the kind of trend we might want to visualize with a chart.
2010 45224
2011 43364
2012 42333
2013 39542
2014 37078
2015 25732
2016 23089
2017 21989
2018 20543
2019 19407
2023 13566
2020 13162
2022 12360
2021 11130
Name: year, dtype: int64
Note
You can read about this long-term trend in stories by the Baltimore Banner, the BBC the Washington Post and the New York Post.
Before we can pass our data into Datawrapper, we need to reshape it into a pandas DataFrame, the kind of data structure that our datawrapper library expects. We can do that by calling the sort_index and reset_index methods on the end of the value_counts method.
totals_by_year = df.year.value_counts().sort_index().reset_index()
That should output a tidy table that’s ready for the API. The only other things you need to make a basic chart are a headline and a chart type. You can write whatever headline you like, but every chart type has a strict code name that you can find in the Datawrapper documentation.
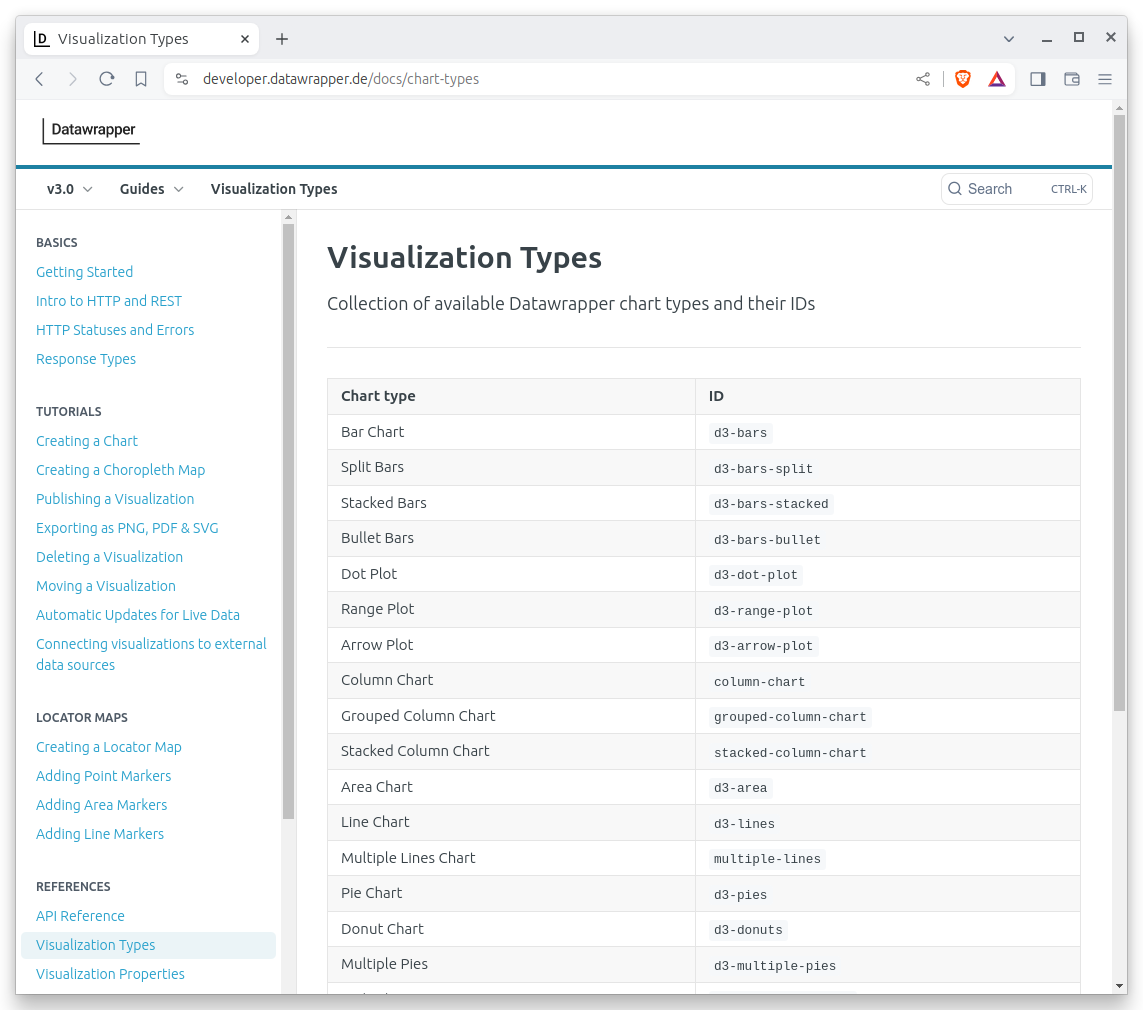
In this case, the data seems well suit for a column chart, with one vertical bar for each year’s arrest total. The documentation tells us that the code for that is “column-chart.”
Connecting to the API and creating your first chart is as simple as passing our three required inputs — a headline, a chart type and a DataFrame — into the create_chart method of the dw object.
That can be done with the following code. While it’s not required, we’ll save the result as a variable named chart so that we can reuse what it returns.
chart = dw.ColumnChart(
title="Baltimore Arrests",
data=totals_by_year
)
Then you can create the chart by running the create method on the chart object.
chart.create()
If the cell runs without error, a new chart is born. You can see it by visiting https://app.datawrapper.de/ in your browser.
Congratulations! You’ve created your first chart using the Datawrapper API. While it’s ready for review in the dashboard, it won’t be published for others to see.
Sending your chart live is as simple as running the publish method on the chart object.
chart.publish()
That will make the chart available to the public.
You can see your handiwork in the notebook by asking the object to show the chart’s embed using the display method.
chart.display()
Set the chart description¶
A common practice in journalism is to provide a citation for the soruce data behind a chart. This is can be done manually in the “Describe” tab of the Datawrapper interface. You can also do it using the update_description method of the dw object. Here we’ll set the source name, source URL and byline.
chart.source_name = "OpenBaltimore"
chart.source_url = "https://data.baltimorecity.gov/datasets/baltimore::bpd-arrests/about"
chart.byline = "First Automated Chart"
chart.update()
Run that cell and republish your chart.
chart.publish()
You can see the changes by, again, asking the dw object to display the chart’s embed. Take a look at the bottom line of the chart to see the citation.
chart.display()
Style the chart¶
You can do much more than that by using Python to configure the chart’s metadata. There are literally dozens of different ways to customize axis labels, annotations, colors, legends, lines, bars and other features.
Note
You can find a list of many of the available options in the Datawrapper documentation.
A simple example is to change the color of the bars. That can be done by setting the base_color attribute of the chart object.
chart.base_color = "#bf7836" # Our accent color
Now you just run update again.
chart.update()
Then if you publish the chart…
chart.publish()
…and display it again…
chart.display()
…you should see the bars have changed color.
Create many charts¶
While using Python to make one chart is a nice trick, it’s also pretty easy to do with a mouse and keyboard. One benefit of automating chart creation with Python is that the code you write to make one chart can be reused to make many charts.
For instance, we could use the tricks we learned making our citywide chart to create a separate chart for each of Baltimore’s police districts.
If you take a look at our sample data again by running the head command, you’ll notice that there is column called “District.”
df.head()
Have a closer at what’s in it by running the value_counts method, just as we did with the year. It will show that there are nine unique districts in the dataset.
df.District.value_counts()
That will return tallies like this:
Western 29842
Central 28501
Eastern 28114
Southern 25780
Northeast 24180
Southeast 23710
Northwest 22044
Southwest 21822
Northern 13087
That means you could use Python and our datawrapper library to create nine different annual arrests charts.
While there are numerous ways to accomplish this task, in this example we’ll write a function that takes the name of a district as an argument and returns a chart. We’ll then use a for loop to call that function for each district.
Here’s a function that does exactly that. We don’t have enough time to walk through every step of it, but if you look closely you can see that it’s very similar to the code we used to create the first chart. You should copy and paste it into a new cell in your notebook.
def create_chart(district: str) -> str:
"""Create a Datawrapper column chart of arrests by year in a Baltimore police district.
Args:
district: The name of the district to chart.
Returns:
The chart's embed code.
"""
# Filter the dataframe to the provided district
district_df = df[df.District == district]
# Count the number of arrests in each year
district_by_year = district_df.year.value_counts().sort_index().reset_index()
# Create the chart with Datawrapper
chart = dw.ColumnChart(
# Use the district name in the title
title=f"Arrests in Baltimore's {district} District",
# Pass in the filtered data
data=district_by_year,
base_color="#bf7836",
source_name="OpenBaltimore",
source_url="https://data.baltimorecity.gov/datasets/baltimore::bpd-arrests/about",
byline="First Automated Chart",
)
# Create the chart
chart.create()
# Publish the chart
chart.publish()
# Return the chart's embed code
return chart.display()
Now all it takes to create a chart is to call the function and pass in the name of a district. For instance, to create a chart for the Western District, you would run the following code:
create_chart("Western")
And to create a chart for the Eastern District, you would run the following code:
create_chart("Eastern")
Finally, we can loop through the list of unique districts and create a chart for each one. We’ll save each chart as a variable in a list so that we can display them all at once. Copy and paste the following code into a new cell in your notebook.
# Create an empty list to hold the charts
chart_list = []
# Loop through the unique districts...
for district in df.District.dropna().unique():
# Print a message to the console
print(f"Creating chart for the {district} District")
# Create a chart for the district and save it as a variable
c = create_chart(district)
# Add the chart to the list
chart_list.append(c)
You can see them all at once in your notebook by introducing the display function from the IPython.display library …
from IPython.display import display
… and passing in the list of charts as arguments.
display(*chart_list)
Not bad, right? You’ve just created a dozen charts in a few seconds. You could do the same with an unlimited number of charts, as long as you have the data to supply the API.
Create a chart that runs on a schedule¶
That’s one example of how Python can supercharge your chart production. Here’s another: You can write computer code that, when run on a schedule, will create a chart. This is a powerful way to publish whenever new records are available.
As an example, let’s automate a chart that could be useful to a newsroom. We’ll create a chart that shows the top 10 arrest charges in Baltimore over the last week. It could, in theory, be published every Monday morning after new data is posted to the city data portal.
First we’ll find the most recent date in our dataset, which will be the end of the week we want to chart. That can be done with pandas by calling the max method on a date column.
df.ArrestDateTime.dt.date.max()
Let’s save that into a variable.
end_date = df.ArrestDateTime.dt.date.max()
Then we’ll use the timedelta class from the datetime module to find the date one week before, which will be the start of our date range.
First we import the tool.
from datetime import timedelta
Then we can subtract seven days from the end date.
seven_days_ago = end_date - timedelta(days=7)
Now filter the dataset to the last week by creating a new DataFrame that only contains the rows where the ArrestDateTime is after the start date.
last_week_df = df[df.ArrestDateTime.dt.date > seven_days_ago]
We can then count the number of arrests for each charge and save the top 10 as a new DataFrame.
top_charges_df = (
last_week_df.ChargeDescription.value_counts() # Count the number of arrests for each charge
.reset_index() # Reset the index so that the charge becomes a column
.head(10) # Save only the top 10
)
Pass that into the create_chart method of the dw object, just as we did before. This time we’ll use the “d3-bars” chart type, which is a nice way to visualize a ranked list of items.
chart = dw.BarChart(
title=f"Top 10 arrest charges in Baltimore last week",
data=top_charges_df, # Note that we're using the top charges DataFrame
base_color="#113421",
thick=True,
source_name="OpenBaltimore",
source_url="https://data.baltimorecity.gov/datasets/baltimore::bpd-arrests/about",
byline="Ben Welsh",
)
Just as we did with our first chart …
chart.create()
… we can publish it …
chart.publish()
… and display it.
chart.display()
Boom. We’re created a little Python routine that, provided with an updated dataset, could be rerun at any time to create a fresh chart.
There are numerous ways you could run such a script according to a schedule, a task beyond the scope of this course. One popular tool is GitHub Actions, a free service linked to GitHub respositories. You can learn how journalists use it to automate data work in our complimentary class “First GitHub Scraper.”
About this class¶
This guide was prepared by Ben Welsh and Sergio Sanchez Zavala for a training session at the National Institute for Computer-Assisted Reporting’s 2024 conference in Baltimore. It was updated in October 2025 to reflect version 2.0 of the datawrapper library. Some of the copy was written with the assistance of GitHub’s Copilot, an AI-powered text generator. The materials are available as free and open source on GitHub.