5. Scaling up more servers¶
Now that we have our initial Actions scraper going, let’s try scraping several states at once. In this chapter, you’ll learn how to take advantage of the parallelization capabilities of Actions.
Actions provides a feature called the matrix strategy that allows programmers to easily run different versions of the same Action in parallel using just a few extra lines of code.
Instead of scraping one state, we can provide a list of states, and Actions will spin up a separate instance of the job for each state — as if we’re renting multiple blank computers from Github. Instead of waiting for one scraper to finish before scraping the next state, multiple jobs can run at the same time on separate instances.
Examples of this technique that we’ve worked on include:
An open-source archive that preserves more than 1,000 news homepages twice per day.
The transcription of hundreds of WNYC broadcast recordings from the New York City Municipal Archive
The collection of WARN Act notices posted by dozens of different states that serves as the example for this class
First, copy the YAML code we worked on in the last chapter into a new workflow file named parallel.yml.
name: First Scraper
on:
workflow_dispatch:
inputs:
state:
description: 'U.S. state to scrape'
required: true
default: 'ia'
schedule:
- cron: "0 0 * * *"
permissions:
contents: write
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ${{ inputs.state }} --data-dir ./data/
- name: Save datestamp
run: date > ./data/latest-scrape.txt
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data for ${{ inputs.state }}" && git push || true
Let’s change the name property to Matrix Scraper. For now, let’s also remove the steps under workflow-dispatch that accept inputs and the scheduling.
name: Matrix Scraper
on:
workflow_dispatch:
permissions:
contents: write
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ${{ inputs.state }} --data-dir ./data/
- name: Save datestamp
run: echo "Scraped ${{ inputs.state }}" > ./data/latest-scrape.txt
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data for ${{ inputs.state }}" && git push || true
5.1. Matrix strategy¶
Take a look at the scraping logic we implemented earlier. Under the scrape job, we will define the matrix strategy. Here, we’d like to provide a list of states to scrape.
name: Matrix Scraper
on:
workflow_dispatch:
permissions:
contents: write
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
strategy:
matrix:
state: [ca, ia, ny]
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ${{ inputs.state }} --data-dir ./data/
- name: Save datestamp
run: echo "Scraped ${{ inputs.state }}" > ./data/latest-scrape.txt
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data for ${{ inputs.state }}" && git push || true
In our original scraper, we combined scraping and committing in a single step because we weren’t worried about first pulling the latest repo changes. However, with multiple jobs running in parallel, we can no longer guarantee their order of completion. In this chapter, we’ll solve that by splitting the action into two steps.
First, we’ll run all scrapers in parallel and save their outputs in temporary storage known as artifacts.
Then, once every job finishes, we’ll collect those Artifacts and make a single commit. This approach ensures that all parallel jobs contribute their changes without overwriting each other.
5.1.1. Error handling¶
GitHub Actions provides two error-handling settings that will be helpful. One is called fail-fast. This flag controls whether the entire matrix job should fail if one job in the matrix fails. In our case, we want to mark this flag as false; even if one state’s scraper fails, we still want the job to be completed and continue scraping the other states.
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
continue-on-error: true
strategy:
fail-fast: false
matrix:
state: [ca, ia, ny]
The second error-handling setting is called continue-on-error. When true, this allows the Action to continue running subsequent steps even if an earlier step fails. Since our Action has multiple jobs—a build job and a commit job—we want the Action to continue running even if one of the scrapes fails earlier.
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
continue-on-error: true
strategy:
fail-fast: false
matrix:
state: [ca, ia, ny]
To accommodate our matrix strategy, we’ll also modify all the steps that use the inputs.state variable to use matrix.state instead. For example, in the “Scrape” step, we change the line to:
- name: Scrape
run: warn-scraper ${{ matrix.state }} --data-dir ./data/
We should do the same for the scraping step. For simplicity, let’s remove that datestamp step for now.
name: Matrix Scraper
on:
workflow_dispatch:
permissions:
contents: write
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
continue-on-error: true
strategy:
fail-fast: false
matrix:
state: [ca, ia, ny]
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ${{ matrix.state }} --data-dir ./data/
5.2. Uploading artifact¶
Now that we’ve scraped our data, we need a place to store it before we commit it to the repo. To do this, we are using Actions Artifacts. Artifacts allow you to persist data after a job has completed and share that data with another job in the same workflow. An artifact is a file or collection of files produced during a workflow run.
Here, we are using the shortcut actions/upload-artifact created by GitHub, which allows us to temporarily store our data within our task.
name: Matrix Scraper
on:
workflow_dispatch:
permissions:
contents: write
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
continue-on-error: true
strategy:
fail-fast: false
matrix:
state: [ca, ia, ny]
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ${{ matrix.state }} --data-dir ./data/
- name: upload-artifact
uses: actions/upload-artifact@v6
with:
name: ${{ matrix.state }}
path: ./data/${{ matrix.state }}.csv
5.3. Commit step¶
Next, let’s create a second step for our Action: the commit step. We’ll start with the standard step of checking out the code. Notice that the step needs the scraping step, which ensures it will not run until our first step has finished.
commit:
name: Commit
runs-on: ubuntu-latest
needs: scrape
steps:
- name: Checkout
uses: actions/checkout@v6
The next step is to download the artifacts we previously stored for use in this step. This is done using the actions/download-artifact companion to the uploader.
commit:
name: Commit
runs-on: ubuntu-latest
needs: scrape
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Download artifact
uses: actions/download-artifact@v7
with:
pattern: '*'
path: artifacts/
To keep our repo clean, we can add a Move step to unpack the artifacts—which are all stored in their own folders since they came from different parallel jobs—and put them into our data/ folder. Lastly, we push with the same code as before.
commit:
name: Commit
runs-on: ubuntu-latest
needs: scrape
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Download artifact
uses: actions/download-artifact@v7
with:
pattern: '*'
path: artifacts/
- name: Move
run: |
mkdir data -p
mv artifacts/**/*.csv data/
We can add a logging step here to save the current date and time to a file. This will help us track when the last scrape was done and prevent GitHub from deactivating the workflow.
commit:
name: Commit
runs-on: ubuntu-latest
needs: scrape
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Download artifact
uses: actions/download-artifact@v7
with:
pattern: '*'
path: artifacts/
- name: Move
run: |
mkdir data -p
mv artifacts/**/*.csv data/
- name: Save datestamp
run: date > ./data/latest-scrape.txt
Finally, we can add the same commit and push step as before. This time, we don’t need to specify the state in the commit message since all states are now included in the data folder.
commit:
name: Commit
runs-on: ubuntu-latest
needs: scrape
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Download artifact
uses: actions/download-artifact@v7
with:
pattern: '*'
path: artifacts/
- name: Move
run: |
mkdir data -p
mv artifacts/**/*.csv data/
- name: Save datestamp
run: date > ./data/latest-scrape.txt
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data" && git push || true
All together, our final code should look like this:
name: Matrix Scraper
on:
workflow_dispatch:
permissions:
contents: write
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
continue-on-error: true
strategy:
fail-fast: false
matrix:
state: [ca, ia, ny]
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ${{ matrix.state }} --data-dir ./data/
- name: upload-artifact
uses: actions/upload-artifact@v6
with:
name: ${{ matrix.state }}
path: ./data/${{ matrix.state }}.csv
commit:
name: Commit
runs-on: ubuntu-latest
needs: scrape
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Download artifact
uses: actions/download-artifact@v7
with:
pattern: '*'
path: artifacts/
- name: Move
run: |
mkdir data -p
mv artifacts/**/*.csv data/
- name: Save datestamp
run: date > ./data/latest-scrape.txt
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data" && git push || true
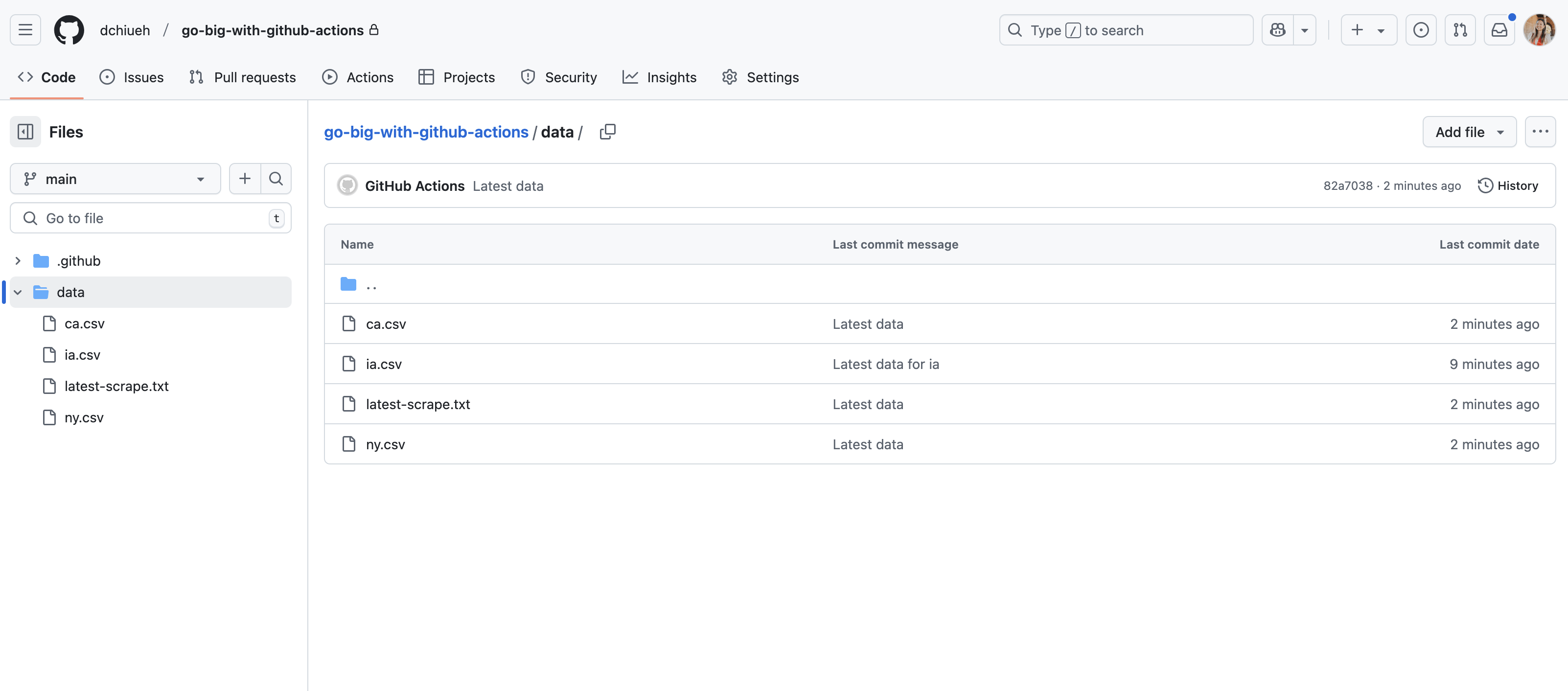
5.4. Breaking our action?¶
What happens when we try to scrape a state that doesn’t exist in the scraper? For example, mn WARN notices are not supported by Big Local News’ WARN Scraper. Let’s try changing our list of scraped states:
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
continue-on-error: true
strategy:
fail-fast: false
matrix:
state: [mn, md, tn, wv, ny]
Now, commit and rerun the action.
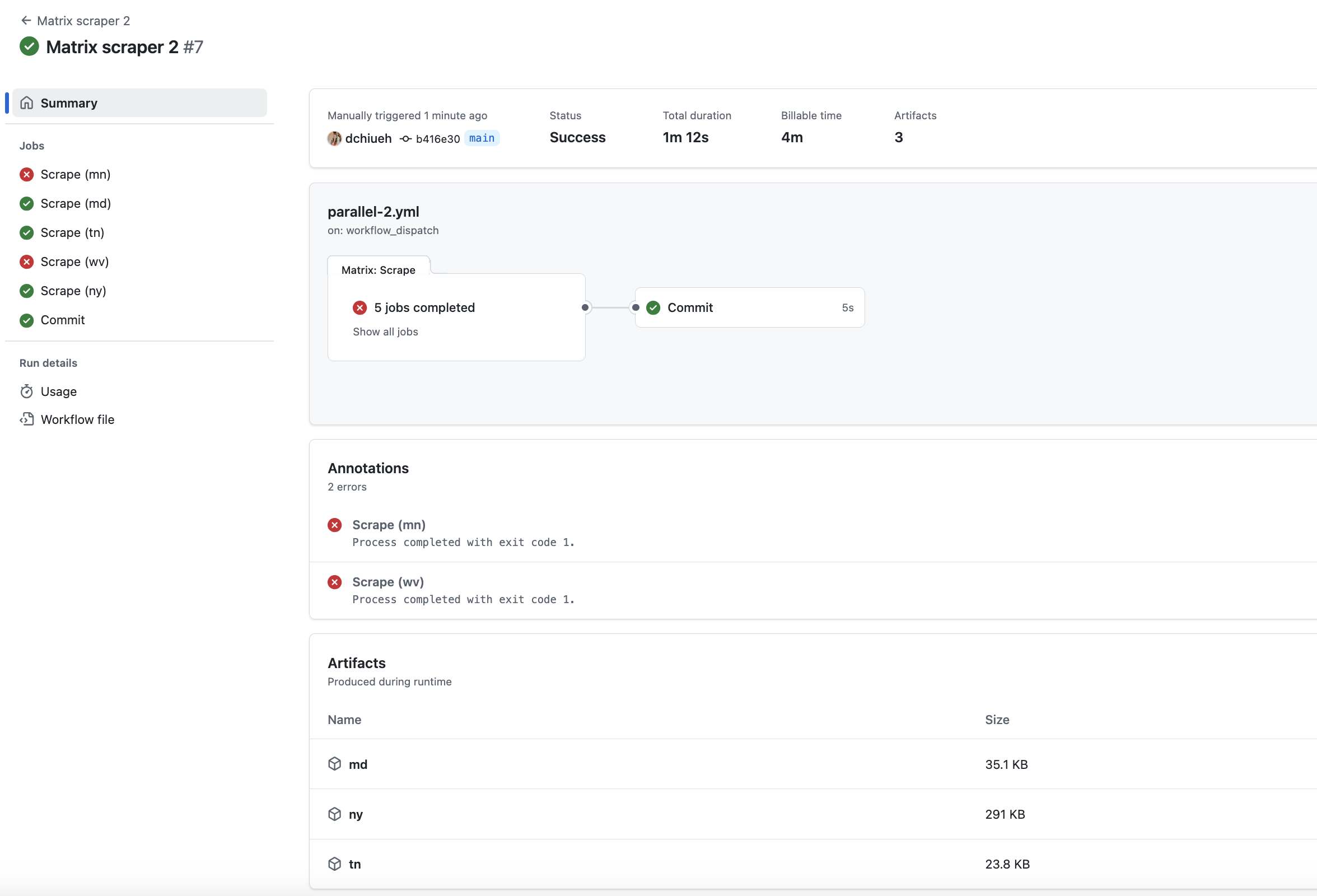
We can see that thanks to fail-fast, mn and wv fail (because the WARN scraper does not support these states), while md, tn and ny succeed. And thanks to continue-on-error, even though there were failures in the first scrape step, the action continued to run to the commit step and push the newly scraped data into the repo.