4. Scraping data on a schedule¶
A web scraper is a computer script that can extract data from a website and store it in a structured format. It’s one of the most common ways to collect information from the web and a favorite tool of data journalists.
Since the web constantly updates, scrapers must run regularly to keep the data fresh. Scheduling routine tasks on a personal computer can be unreliable, and many cloud services can be expensive or difficult to configure. And then there’s the tricky bit of figuring out where you’ll store the data.
This is an area where GitHub Actions can help. Building on the fundamentals we covered in the previous chapter, we can schedule a workflow that will run a web scraper and store the results in our repository — for free!
Examples of Actions scrapers that we’ve worked on include:
The Reuters system that extracts the famous ‘dot plot’ economic projections issued by the U.S. Federal Reserve
Dozens of COVID-19 data scrapers developed at the Los Angeles Times
A routine that collects and parses animal welfare inspections conducted by the U.S. Department of Agriculture
4.1. Create a new workflow¶
Let’s begin by starting a new workflow file. Go to your repository’s homepage in the browser. Click on the “Actions” tab, which will take you to a page where you manage Actions. Now click on the “New workflow” button.
Click the “set up a workflow yourself” link again.
This time let’s call this file scraper.yml.
4.2. Write your workflow file¶
Start with a name and expand the on parameter we used last time by adding a cron setting. Here, we’ve added a crontab expression that will run the Action every day at 00:00 UTC.
name: First Scraper
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
Note
Crons, sometimes known as crontabs or cron jobs, are a way to schedule tasks for particular dates and times. They are a powerful tool but a bit tricky to understand. If you need help writing a new pattern, try using crontab.guru.
Next, add a simple job named scrape.
name: First Scraper
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
Think of Actions as renting a blank computer from GitHub. To use it, you will need to install the latest version of whatever language you are using, as well as any corresponding package managers and libraries.
Because these Actions are used so often, GitHub has a marketplace where you can find pre-packaged steps for common tasks.
The checkout action clones our repository onto the server so that all subsequent steps can access it. We will need to do this so that we can save the scraped data back into the repo at the end of the workflow.
name: First Scraper
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
Our scraper will gather the latest mass layoff notices posted on government websites according to the U.S. Worker Adjustment and Retraining Notification Act requirements, also known as the WARN Act. It’s an open-source software package developed by Big Local News, which uses the Python computer programming language.
So our next step is to install Python, which can also be accomplished with a pre-packaged action.
name: First Scraper
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
Now we will use Python’s pip package manager to install the warn-scraper package.
name: First Scraper
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
According to the package’s documentation, all we need to do to scrape a state’s notices is to type warn-scraper <state> into the terminal.
Let’s scrape Iowa, America’s greatest state, and store the results in the ./data/ folder at the root of our repository.
name: First Scraper
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ia --data-dir ./data/
Finally, we want to commit this scraped data to the repository and push it back to GitHub.
name: First Scraper
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ia --data-dir ./data/
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data for Iowa" && git push || true
Save this workflow to our repo. Go to the Actions tab, choose your scraper workflow, and click Run workflow, as we did in the previous chapter.
Once the task has been completed, click its list item for a summary report. You will see that Action was unable to access the repository. This is because GitHub Actions requires that you provide permissions.
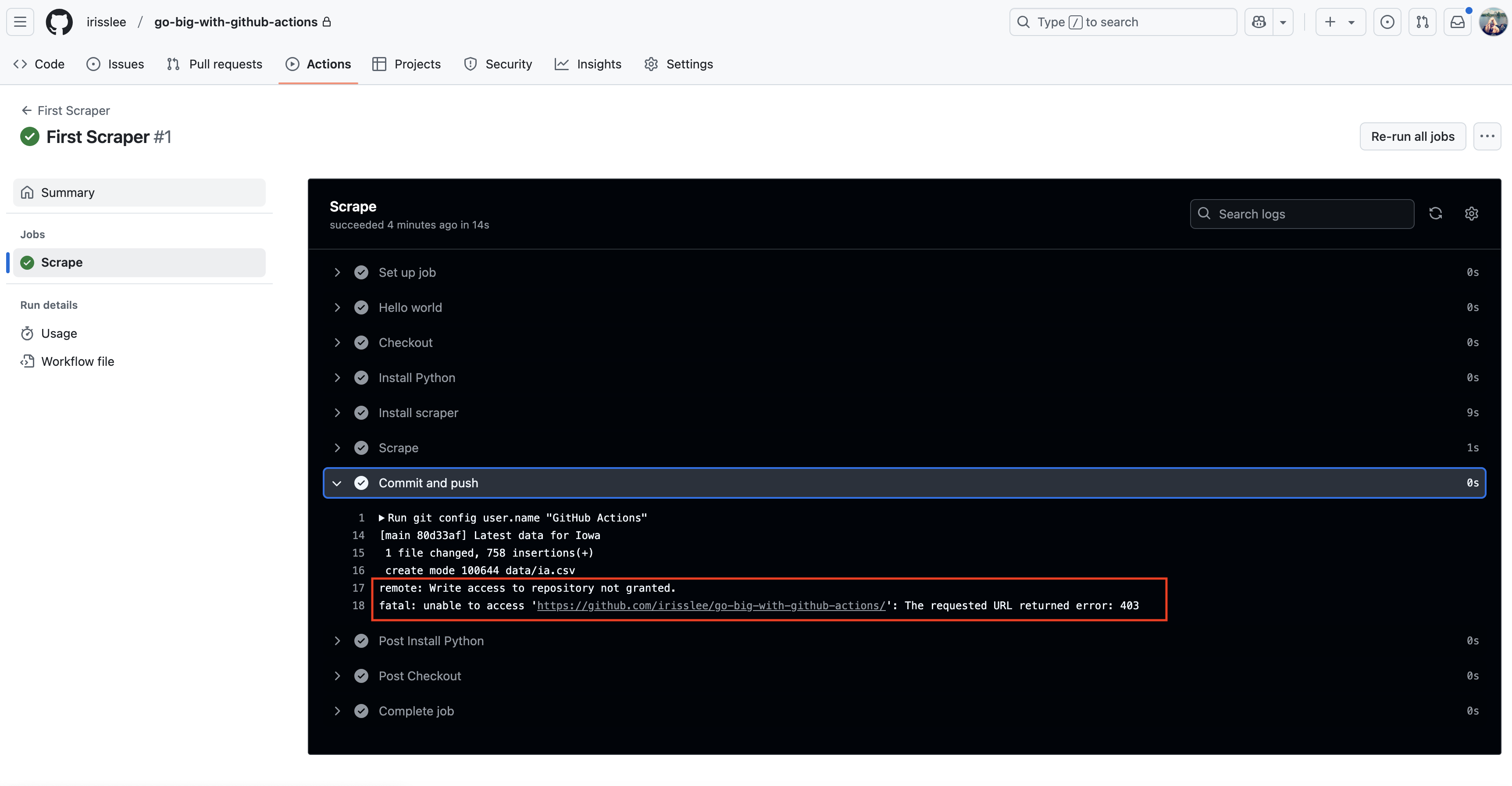
Let’s go ahead and add the line so that we can provide write permission to all jobs.
name: First Scraper
on:
workflow_dispatch:
schedule:
- cron: "0 0 * * *"
permissions:
contents: write
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ia --data-dir ./data/
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data for Iowa" && git push || true
Save the file and rerun the Action.
Once the workflow has been completed, you should see the ia.csv file in your repository’s data folder.
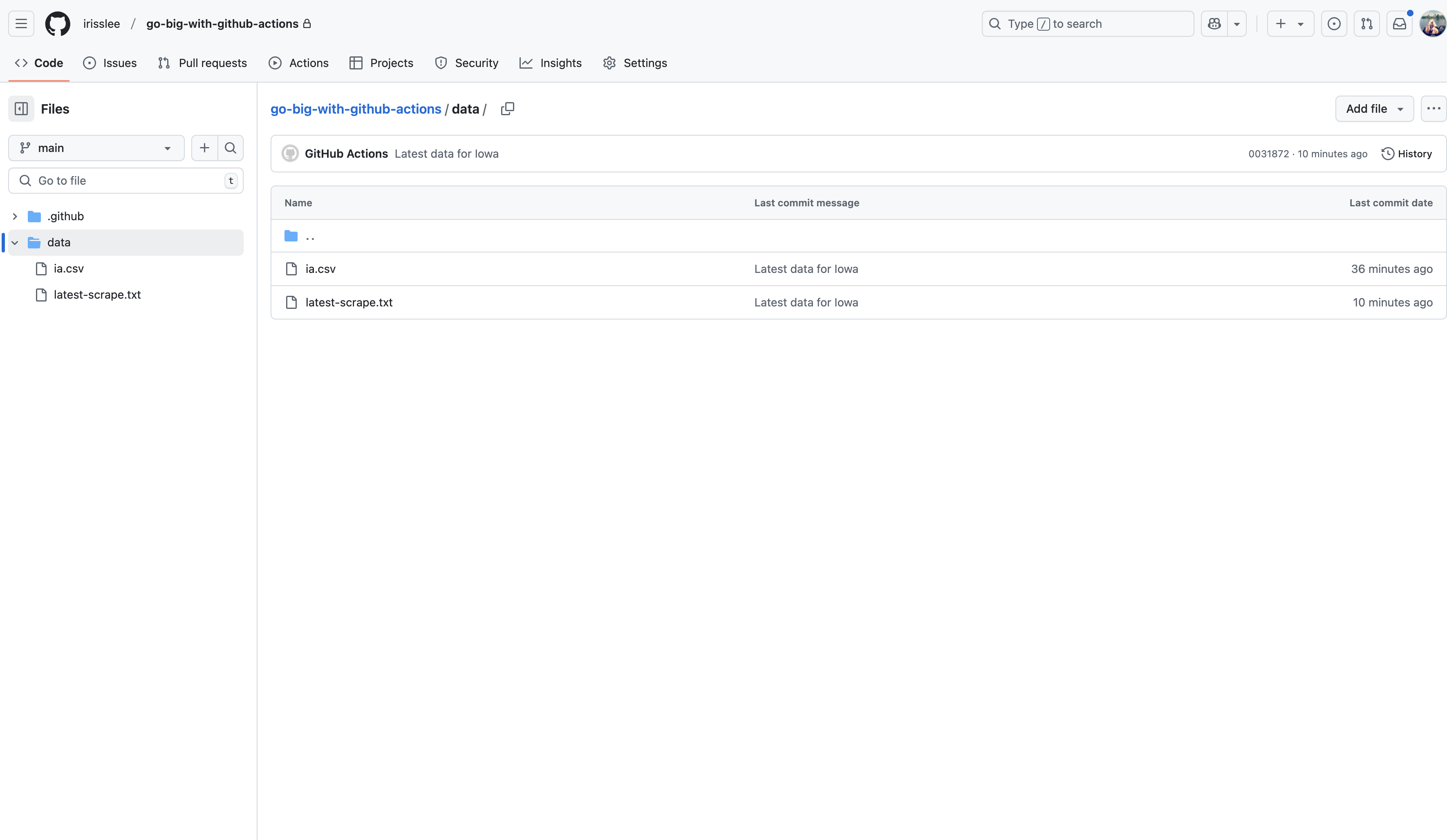
4.3. User-defined inputs¶
GitHub Actions allows you to specify inputs for manually triggered workflows, which we can enable users to specify what state to scrape.
To add an input option to your workflow, go to your YAML file and add the following lines. Here, we ask Actions to create an input called state. A given Action can have more than one input.
If you need more control over your inputs, you can also add choices.
name: First Scraper
on:
workflow_dispatch:
inputs:
state:
description: 'U.S. state to scrape'
required: true
default: 'ia'
schedule:
- cron: "0 0 * * *"
Once your input field has been configured, let’s change our warn-scraper command so that whatever we input as state will be reflected in the scrape command.
- name: Scrape
run: warn-scraper ${{ inputs.state }} --data-dir ./data/
4.3.1. Customize your commit message¶
You can add these inputs anywhere! Add them to your commit message for accuracy.
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data for ${{ inputs.state }}" && git push || true
4.3.2. Add a datestamp¶
GitHub may automatically disable workflows if there’s a period of inactivity. To get around this you can have your workflow commit an updated text file every time your Action runs.
- name: Save datestamp
run: date > ./data/latest-scrape.txt
4.4. Final steps¶
Your final file should look like this.
name: First Scraper
on:
workflow_dispatch:
inputs:
state:
description: 'U.S. state to scrape'
required: true
default: 'ia'
schedule:
- cron: "0 0 * * *"
permissions:
contents: write
jobs:
scrape:
name: Scrape
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v6
- name: Install Python
uses: actions/setup-python@v6
with:
python-version: '3.12'
- name: Install scraper
run: pip install warn-scraper
- name: Scrape
run: warn-scraper ${{ inputs.state }} --data-dir ./data/
- name: Save datestamp
run: date > ./data/latest-scrape.txt
- name: Commit and push
run: |
git config user.name "GitHub Actions"
git config user.email "actions@users.noreply.github.com"
git add ./data/
git commit -m "Latest data for ${{ inputs.state }}" && git push || true
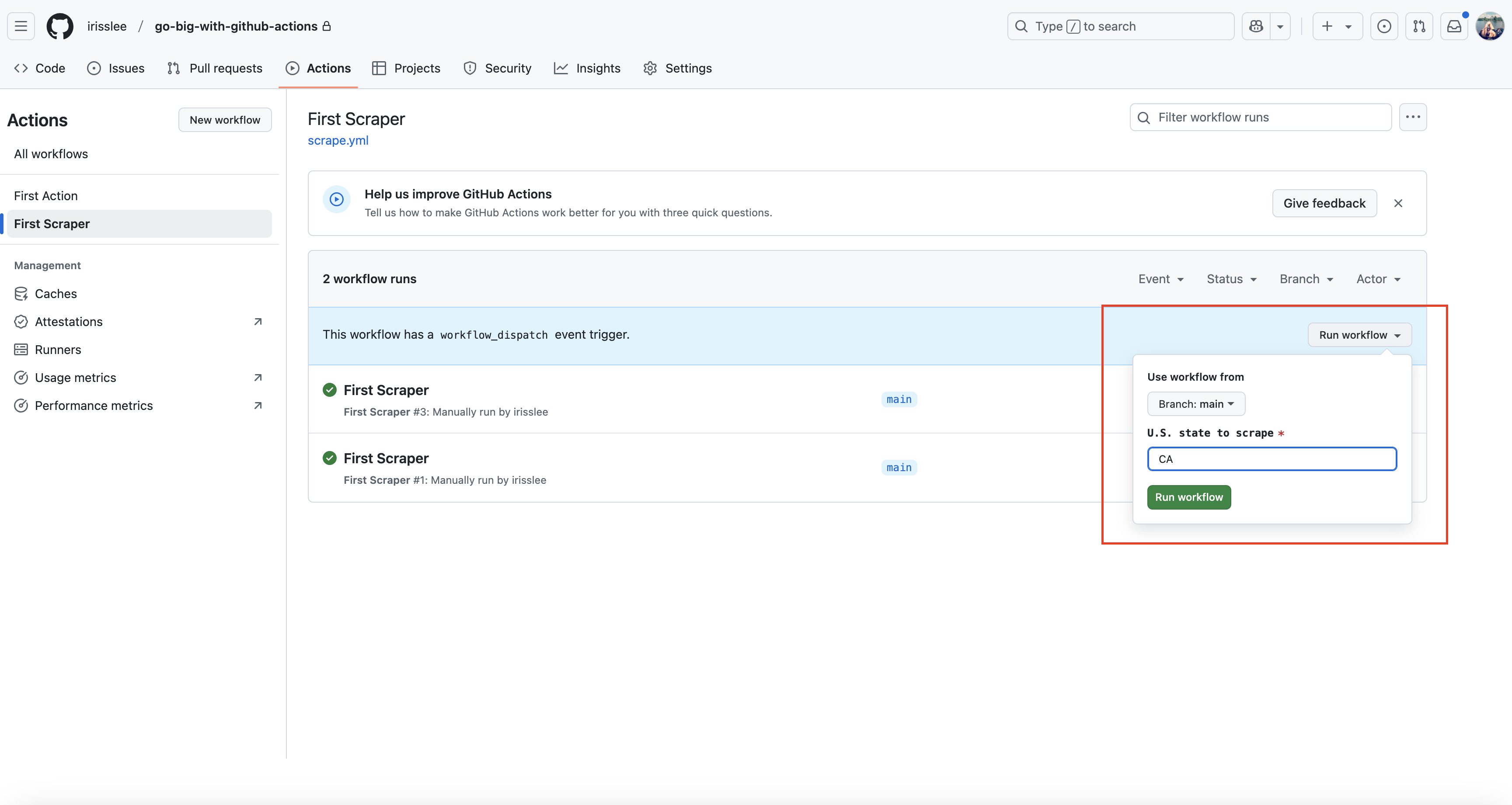
Let’s rerun the Action. Now when you go to run your Action, you will see an input field. This will allow you to specify which state to scrape for. Here I’m choosing CA.
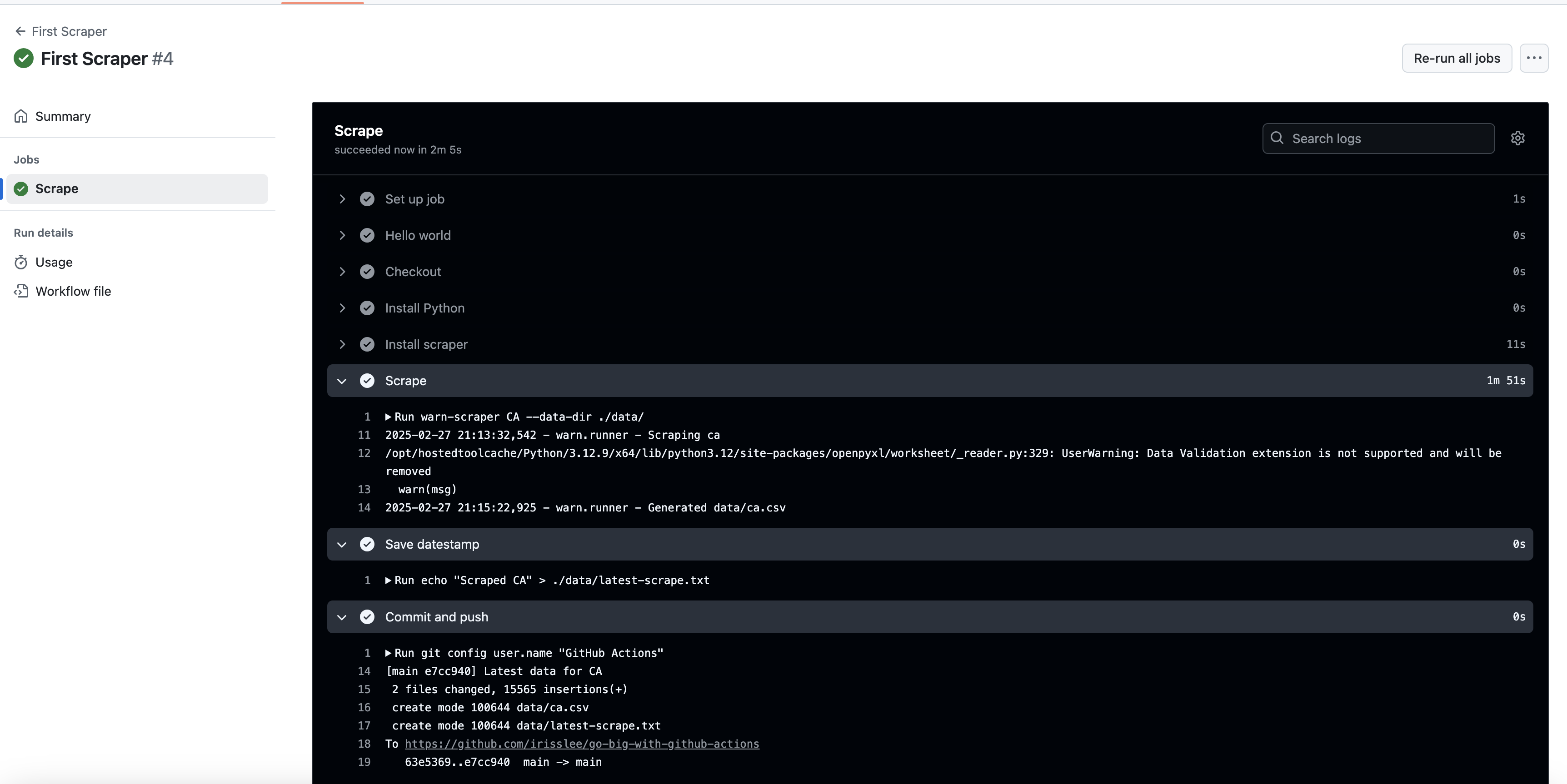
Upon completion, you will see that steps that reference inputs.state have been run with the correct value.
Note
You are not limited to third-party packages like warn-scraper. You can run any script you include in your repository.
If you’d like an example to try out, check out the scrape.ipynb Jupyter notebook in this project’s repository, which is run as part of this workflow.